 |
 |
Section 7: PyDmed Process Tree
PyDmed is implemented using python multiprocessing. You don’t need to know about multiprocessing. But this section introduces some general variables so that you can get the best performance from PyDmed based on your machine (s).
The hierarchy of processes
The below figure illustrates the process tree of PyDmed.
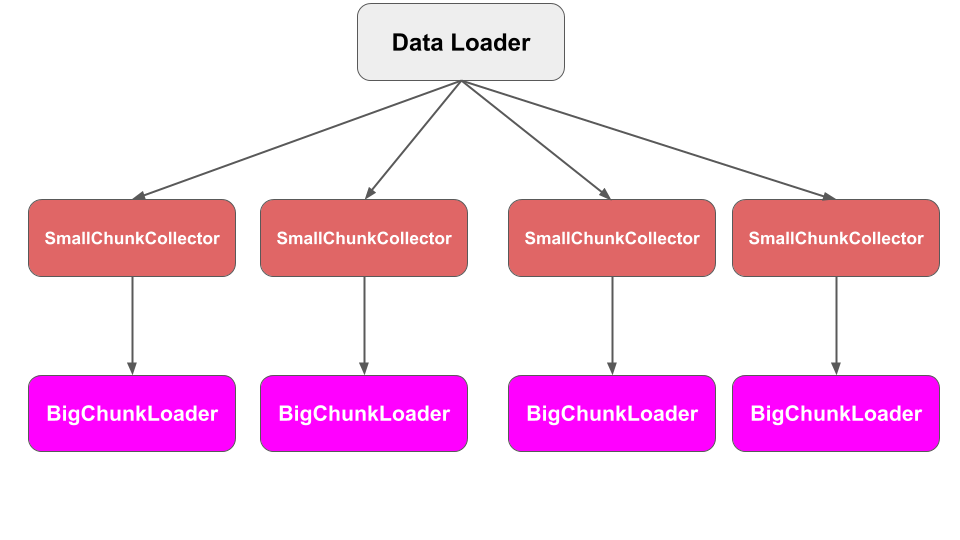
Each BigChunkLoader is a child (i.e. subprocess) of a SmallChunkCollector.
Once the BigChunk is loaded, the BigChunkLoader iteself is terminated. But the parent SmallChunkCollector
will continue working on the BigChunk.
Each SmallChunkCollector (and its child BigChunkLoader) correspond to one Patient.
Indeed, a SmallChunkCollector and the child BigChunkLoader work on a specific Patient.
Moreover, the dataloader makes sure that at all times at most one active SmallChunkCollector works on a specific Patient.
Life Cycle of Subprocesses
In regular intervals:
- The scheduler selects a patient from the dataset.
- A
BigChunkLoaderextracts a big chunk from the patient’s records. TheBigChunkLoaderhas access to the patient byself.patient. - The extracted big chunk is passed to a
SmallChunkCollector. TheSmallChunkCollectorhas access to the patient byself.patient.
Tailoring the dataloader to your machine (s)

The parameters of the dataloader are managed by a dictionary called const_global_info.
It has the following fields:
const_global_info["num_bigchunkloaders"]: an integer. Is the number of runningBigChunkLoaders. According to the process tree, this number is also equal to the number of runningSmallChunkCollectors.const_global_info["maxlength_queue_smallchunk"]: an integer. Maximum length of the queues containingSmallChunks. The above figure illustrates those queues: queue_1, queue_2, …, and queue_5.const_global_info["maxlength_queue_lightdl"]: an integer. The maximum length of the dataloader’s queue. In the above figure, this queue is the queue at the top that moves to right-left and collectsSmallChunks to send to GPU(s).-
const_global_info["interval_resched"]: a floating point number. The regular intervals at which the dataloader terminates one of theSmallChunkCollectors and starts a newSmallChunkCollector(and its childBigChunkLoader). const_global_info["core-assignment"]: This field lets you assign the processes in the process tree to different cores. For instance, the following code assigns the dataloader,SmallChunkCollectors andBigChunkLoaders to cores {4}, {0}, {1,2,3}, respectively.const_global_info["core-assignment"] = { "lightdl":"4", "smallchunkloaders":"0", "bigchunkloaders":"1,2,3" }Core assignment uses taskset and is only supported for linux.
As we saw in section 2 we can use the default const_global_info as follows:
const_global_info =\
pydmed.lightdl.get_default_constglobinf()
Here are some points that may help you customize const_global_info:
- having very large queues (i.e. large values for “maxlength_queue_lightdl” and “maxlength_queue_smallchunk”) increases memory usage.
- Loading a
BigChunkis a slow process. Therefore, setting “interval_resched” to a small value may result in frequent IO requests beyond hard disk reading speed. - In the process tree, the dataloader process is essential. It may so happen that
SmallChunkCollectors take over the cores and cause the dataloader process (i.e. the root process in the tree) to starve. PyDmed automatically avoids this issue by using os.nice. To further avoid this issue, in linux machines you can use thecore-assignmentfield.
|
|